
Browser Fingerprinting and Concealing Selenium
I recently discovered a website that would respond to requests normally in Chrome, but failed to display anything when Chrome was being controlled by Selenium. Upon investigation, I discovered both Browser Fingerprinting and a way to have the site display correctly when accessed via Selenium WebDriver.
What is Browser Fingerprinting?
When you browse to a website, JavaScript executing on that website can query a number of things that, when aggregated, can produce a unique identifier, or fingerprint, that represents your browser or device. By querying for data that is often persistent over time, this same fingerprint can be generated determinatively regardless of clearing cookies or accessing via private/incognito modes, and can be used to track your activity over time and across websites. Examples include querying browser version, detecting installed browser extensions and, (for older browsers) determining history by inspecting the :visited CSS selector.
Fingerprint generation can also work cross-browser by using techniques that produce the fingerprint from the underlying device. For example, Canvas Fingerprinting uses WebGL to produce fingerprint variations from GPU hardware and graphics drivers. Similarly, querying for device font-availability could also return similar results cross-browser.
What is FingerprintJS?
It’s an open-source JavaScript library that will perform the fingerprinting for you. A commercial version exists which adds further functionality including Bot Detection which amongst others attempts to identify;
- Selenium combinations (FF, Chrome, IE etc)
- Chrome Headless
- Crawl engines/bots
Accessing a site that implements FingerprintJS Pro via Selenium displays nothing, and running the same request in Postman throws a 429 - Too many requests error. Inspecting requests when we run Chrome ourselves seems to Just Work, but if we enable Preserve Logs we can see the fingerprinting requests (though not the response content).
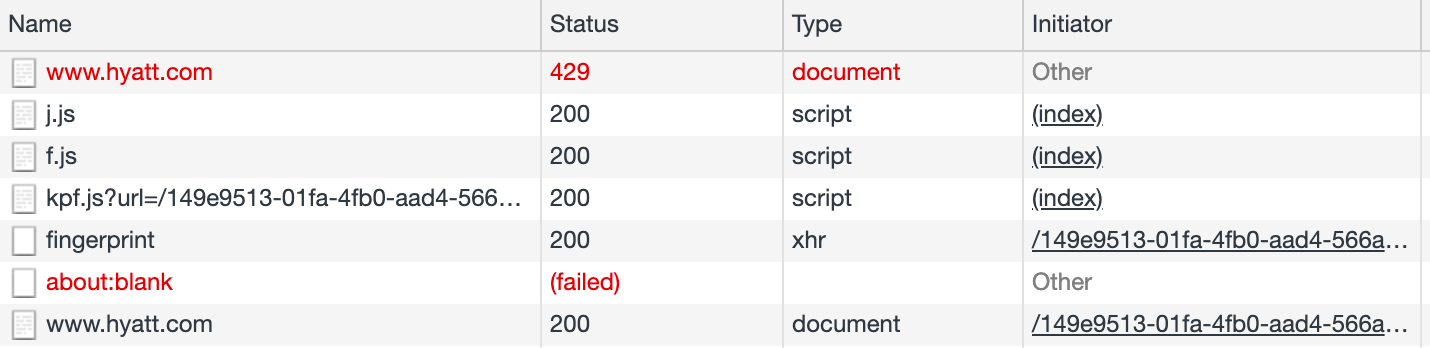
The first request fails with 429 as it is absent a validated cookie. This request however still includes content, in the form of script references to j.js, f.js and kpf.js, and a pre-validated cookie. The call to kpf.js (using the pre-validated cookie) includes a second cookie which is used in the XHR to fingerprint whose response includes a third, validated cookie. This validated cookie is then used in a reloaded request to the original address which now succeeds with 200.
Subsequent requests no longer throw 429 or attempt to fingerprint for as long as the validated cookie remains cached. Clearing the cookie triggers the fingerprinting process again on the next request.
Solving for automated processes
The findings above mean any automated process accessing the site must;
- Be able to execute JavaScript and, in the case of Selenium;
- Conceal the presence of (Selenium) WebDriver
Selenium obviously already executes JavaScript so all we need to do is conceal the presence of WebDriver. The following displays the solution for C#, the same can be seen for Python here.
var driver = new ChromeDriver();
driver.ExecuteChromeCommand("Page.addScriptToEvaluateOnNewDocument",
new System.Collections.Generic.Dictionary<string, object> {
{ "source", @"
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})"
}
}
);Prior to the above, the fingerprinting process will call nagivator.webdriver, receive true, and fail. With the call returning undefined, the fingerprinting process succeeds and the site loads.
Happy scraping!