
Grafana in Kubernetes
After messing with Elasticsearch I’ve decided that my Application Insights replacement could instead be PostgreSQL and Grafana. In this post I’ll install Grafana and set up back-ups and restore functionality in my Kubernetes cluster.
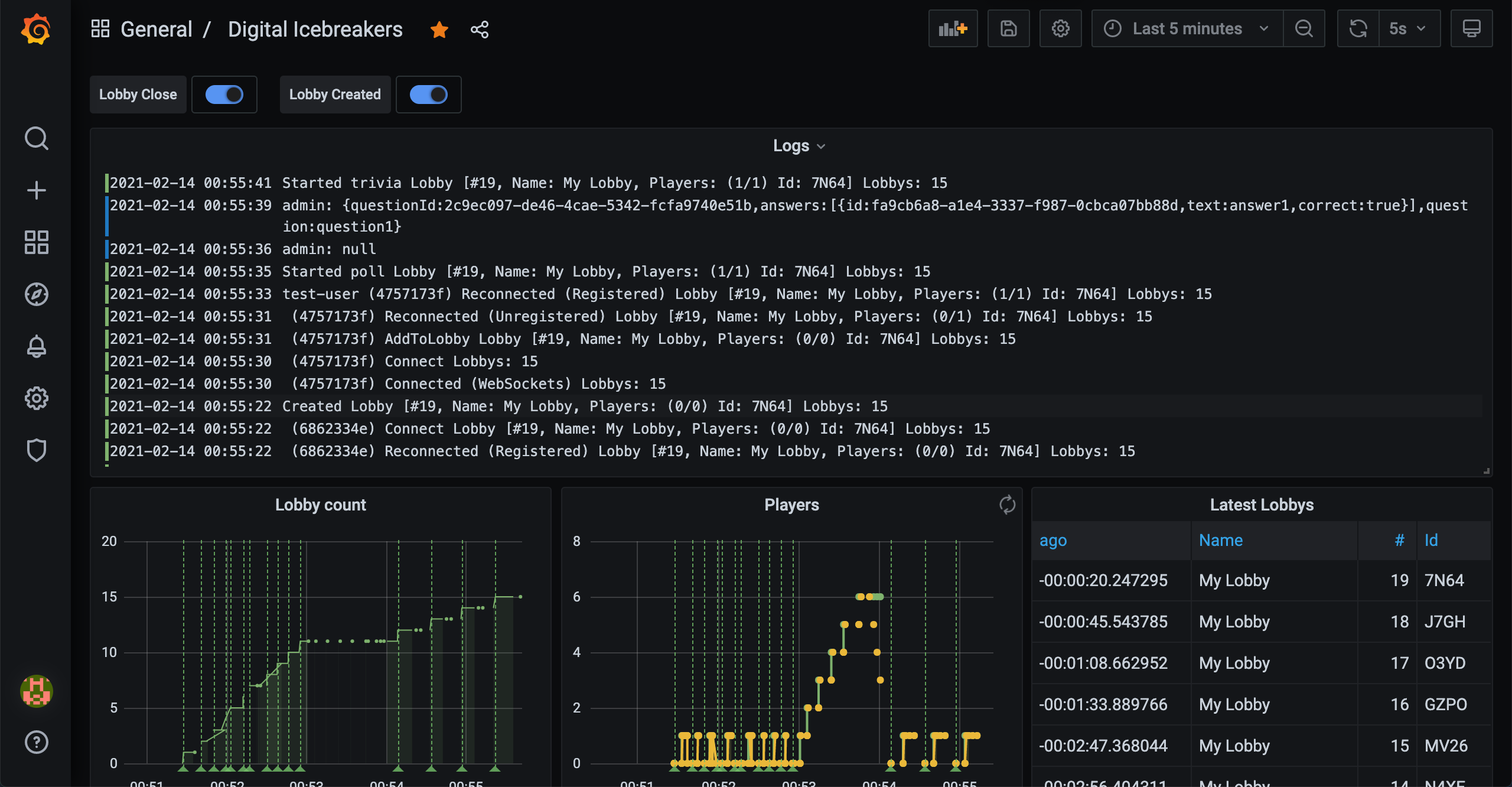
In a previous post I installed PostgreSQL to my cluster and I recently updated Digital Icebreakers to log to PostgreSQL. With log aggregation sorted I needed some way to visualise them and for this I turned to Grafana. Grafana will let me design my own Dashboards and Alerts that will reflect Datasources I’ve made available to it.
Approach
A helm chart is available and default installation is trivial. While a persistent volume can be configured via persistence.enabled=true, instead I’ll run the container without persistence and periodically trigger backup to S3. This approach will also let me restore from backup, allowing setup and tear-down whenever, and wherever, I please. I’ll be using ysde/grafana-backup-tool to backup and restore which I’ve forked with an edit to how S3 folders are created.
Because the Grafana REST API does not expose Datasource passwords the backup tool cannot backup, nor restore these passwords, requiring passwords be set via web interface after restore. However, I want a fully automated solution, so I’ll be defining Datasources via helm install.
Installing via Helm Chart
I’ve specified the following values.yml file where I’ve configured the PostgreSQL database that Digital Icebreakers logs to:
# values.yml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- id: 1
uid: rkYrpQYGk
orgId: 1
name: PostgreSQL
type: postgres
typeLogoUrl: public/app/plugins/datasource/postgres/img/postgresql_logo.svg
access: proxy
url: postgres-postgresql.default.svc.cluster.local:5432
password: ''
user: postgres
database: digital_icebreakers
basicAuth: false
isDefault: true
jsonData:
postgresVersion: 903
sslmode: disable
readOnly: falseI found that the Grafana Logs Panel had issues on the latest stable version, so instead I’m installing from the main branch. I have my PostgreSQL password in a Secret so I’ll override the datasource password with the value from the secret:
POSTGRES_PASSWORD=$(kubectl get secret postgres-postgresql \
-o jsonpath="{.data.postgresql-password}" | base64 --decode)
helm install grafana grafana/grafana \
--values ./values.yml \
--set image.tag=master \
--set-string "datasources.datasources\.yaml.datasources[0].password=$POSTGRES_PASSWORD"Once the chart is up, I can kubectl port-forward svc/grafana --address 0.0.0.0 9000:80, browse to my local on https://localhost:9000 and configure my dashboards. The portal’s username is admin and the password is available via secret:
GRAFANA_PASSWORD=$(kubectl get secret grafana -o jsonpath="{.data.admin-password}" | base64 --decode)Configuring an API Token
To perform backups and restores I’ll need an API Token. This can be set via Grafana’s web interface via Configuration > API Keys but, this also needs to be automated. Once I’ve created the token I’ll stick it in a Secret so the backup job and restore script can use it later.
# create-token.sh
GRAFANA_HOST="192.168.2.50:9000" # my local machine
KEYNAME="apikeycurl-$(date "+%Y%m%d-%H%M%S")"
REQUEST_BODY=$(cat <<EOF
{
"name": "$KEYNAME",
"role": "Admin"
}
EOF
)
GRAFANA_PASSWORD=$(kubectl get secret grafana \
-o jsonpath="{.data.admin-password}" | base64 --decode)
NEW_TOKEN_URL="http://admin:$GRAFANA_PASSWORD@$GRAFANA_HOST/api/auth/keys"
echo Creating Grafana API key...
NEW_TOKEN=$(curl -s -X POST -H "Content-Type: application/json" \
-d "$REQUEST_BODY" $NEW_TOKEN_URL | docker run -i stedolan/jq -r .key)
echo Key created
kubectl delete secret grafana-token --ignore-not-found
kubectl create secret generic grafana-token --from-literal=token=$NEW_TOKENBacking-up via My Local
I built an image from the forked backup tool and while kubectl port-forwarded I can use it to backup Grafana from my local. The S3 variables are the same as my postgres backup job.
# backup.sh
S3_ACCESS_KEY=$(kubectl get secret s3-postgres-backup \
-o jsonpath="{.data.S3_ACCESS_KEY_ID}" | base64 --decode)
S3_SECRET_ACCESS_KEY=$(kubectl get secret s3-postgres-backup \
-o jsonpath="{.data.S3_SECRET_ACCESS_KEY}" | base64 --decode)
S3_BUCKET=$(kubectl get secret s3-postgres-backup \
-o jsonpath="{.data.S3_BUCKET}" | base64 --decode)
GRAFANA_TOKEN=$(kubectl get secret grafana-token \
-o jsonpath="{.data.token}" | base64 --decode)
echo Backing-up Grafana...
docker run --rm --name grafana-backup-tool \
-e GRAFANA_TOKEN=$GRAFANA_TOKEN \
-e GRAFANA_URL=http://$GRAFANA_HOST \
-e VERIFY_SSL=False \
-e AWS_S3_BUCKET_NAME=$S3_BUCKET \
-e AWS_S3_BUCKET_KEY="remote/grafana" \
-e AWS_ACCESS_KEY_ID=$S3_ACCESS_KEY \
-e AWS_DEFAULT_REGION=us-west-2 \
-e AWS_SECRET_ACCESS_KEY=$S3_SECRET_ACCESS_KEY \
staff0rd/grafana-backup-toolBacking-up as a CronJob
The cluster will be scheduling backups itself via CronJob. The environment variables used above are all secrets so the CronJob manifest references them.
# backup-cronjob.yml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: grafana-backup
spec:
schedule: "40 0 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
containers:
- name: grafana-backup
image: staff0rd/grafana-backup-tool
imagePullPolicy: Always
env:
- name: GRAFANA_TOKEN
valueFrom:
secretKeyRef:
name: grafana-token
key: token
- name: GRAFANA_URL
value: http://grafana
- name: VERIFY_SSL
value: "False"
- name: AWS_S3_BUCKET_NAME
valueFrom:
secretKeyRef:
name: s3-postgres-backup
key: S3_BUCKET
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: s3-postgres-backup
key: S3_ACCESS_KEY_ID
- name: AWS_DEFAULT_REGION
value: us-west-2
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: s3-postgres-backup
key: S3_SECRET_ACCESS_KEY
- name: AWS_S3_BUCKET_KEY
value: remote/grafana
restartPolicy: NeverThe manifest can be deployed and the backup job is then scheduled to execute once every 24 hours:
kubectl apply -f backup-cronjob.ymlIf I want to perform the backup immediately from within the cluster, I can use the --from=<cronjob> syntax:
# backup-now.sh
kubectl delete job grafana-backup-now-$(date +"%Y-%m-%d") --ignore-not-found
kubectl create job --from=cronjob/grafana-backup grafana-backup-now-$(date +"%Y-%m-%d")Restoring from Backup
While kubectl port-forwarding I can trigger a restore using the same backup tool. I have the AWS CLI installed and I’ll use it to find the latest Grafana backup in my S3 bucket.
# restore.sh
LATEST_BACKUP=$(aws s3 ls stafford-postgres/remote/grafana/ \
--recursive | sort | tail -n 1 | awk '{print $4}')
echo Latest backup is $LATEST_BACKUP...
echo Restoring Grafana...
docker run --rm --name grafana-backup-tool \
-e GRAFANA_TOKEN=$GRAFANA_TOKEN \
-e GRAFANA_URL=http://$GRAFANA_HOST \
-e VERIFY_SSL=False \
-e RESTORE="true" \
-e AWS_S3_BUCKET_NAME=$S3_BUCKET \
-e AWS_S3_BUCKET_KEY=$(dirname $LATEST_BACKUP) \
-e AWS_ACCESS_KEY_ID=$S3_ACCESS_KEY \
-e AWS_SECRET_ACCESS_KEY=$S3_SECRET_ACCESS_KEY \
-e AWS_DEFAULT_REGION=us-west-2 \
-e ARCHIVE_FILE=$(basename $LATEST_BACKUP) \
staff0rd/grafana-backup-toolConclusion
And with that I have Grafana running and periodically backed up. Any changes I make to dashboards or alerts will be backed-up the next time the CronJob executes or whenever I call ./backup-now.sh.