
LLM Agent Assisted Coding
As a software developer of many years I’m rather enthusiastic in finding ways to improve the efficiency that I write code. I’m already using Copilot auto-complete for any line of code I write but I’ve struggled to find any tool that can go past auto-complete. That is, until I discovered Claude Sonnet 3.5 combined with Model Context Protocol (MCP) servers. After some initial false starts I was able to point the tool to an empty repo and instruct it to:
- Add vite + react + typescript
- Raise a simple home page
- Add mui
- Create and iteratively change components
- Fix any errors/bugs as a response to me copy/pasta the error (and if at run/test time the stacktrace)
- Improve my local experience by configuring an express server to git pull & npm i on github webhook and integrate it with vite hmr 🤯🤯
- Find 🤯 and integrate 🤯 a 3rd party public api
- Add a github workflow to build and deploy the result to netlify 🤯🤯
- Add vitest + react testing library 🤯 + a component test 🤯and include it in the github workflow 🤯
- Read, respond and close github issues, create branches & open PRs. 🤯
See the repo, commits, deployment pipeline and link to netlify here, and full transcript of the session here. The rest of this post details the experience I had with the tool.
- Setup
- Recovering from errors
- First commits
- Editing existing code
- Improving my workflow
- Integrating a public api
- Adding a deployment pipeline
- Adding tests
- Navigating GitHub
- Conclusion
Setup
Configuring the tool at the very least requires a technical understanding but also might include some local forking of additional open source repos. Downloading and installing the Claude desktop client is a few clicks, but there is complexity in configuring the Model Context Protocol (MCP) servers that allow the integration of additional services. In this post, I use two of the reference servers to allow the client to search the internet and interact with GitHub. For each, this requires copying the relevant JSON from the server’s README, choosing Docker or NPX to run it, and setting the API key for the service it will automate.
I created an empty git repo and asked the LLM to add a vite + react + typescript project to it. Each time the LLM responds to a prompt it may determine that one (or more) of the MCP services should be called and it will construct a request and have the client send it to the server. For any action an MCP server exposes, the first time it is called the client will display a dialog with the request content and permission to send it. By choosing Allow Once you can continue to inspect that action every time. Choosing Allow for This Chat will allow the LLM to prompt it without further confirmation.
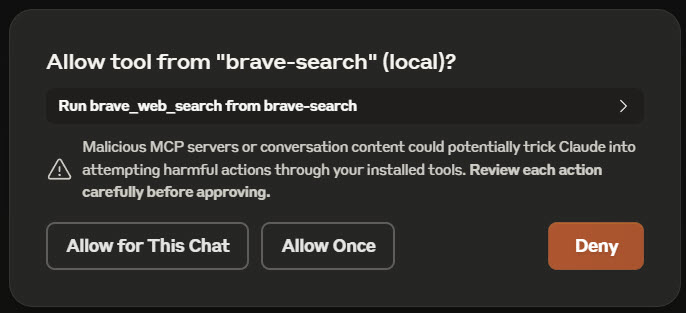
tool permission request dialog
Recovering from errors
It doesn’t always get the syntax of the code it’s writing or the MCP requests it’s making correct.
In the case of bad MCP requests, when it receives an error it will essentially prompt itself with the error message, devise a fix, and immediately retry without any input from the user (except for the MCP permissions dialog in the case I haven’t allowed that server’s action). In my testing, if my prompt was explicit enough such that it could derive the correct MCP action to call, and syntax was the only issue, 100% of the time it was able to automatically fix the issue after one or two tries without my input. In the case it hits the third failure it will stop and ask for help.
In the case of the GitHub server my prompting would consistently result in errors the LLM could not resolve. The issue list revealed a PR with a rewrite of the server and forking the author’s repo and running the server solved the errors.
On the code side, it won’t see any of the errors because it’s not compiling or running the code. So, when I pull latest and run it, there is a chance I’ll see a compile-time or runtime errors. When this occurred, I prompted it with the error message and and it was able to fix the issue. In one case, a test failed and there was a large stack trace which I did not provide in its entirety, rather I summarised it. After a few back-and-forths it was unable to solve the issue, so I paste the entire stack trace and it was able to fi the issue. This kind of reminds me of my own interactions supporting users or other developers where they have communicated something “doesn’t work” and I’ve had to ask for more information before I’ve had any chance of either understanding, isolating, or solving the issue.
First commits
The inclusion of the GitHub MCP server means that the agent will be pushing files directly to the repo via the GitHub API. Notably this means it does not have access to the local filesystem or any CLI tools including compilers, linters, or the npm CLI. It is essentially hand crafting every file and I’m validating they are correct locally by running git pull && npm i && npm run dev. The first valid commit I produced as the result of prompting was a package.json with vite + react + typescript. Obviously a package.json on its own is not enough to bring up a simple vite project, so I prompted the LLM with the error message I received from running npm run dev, and it added the missing files including typescript and vite configs and the initial react components. This is somewhat impressive considering it’s unlikely a human would handcraft these and instead would use something like npm create vite@latest
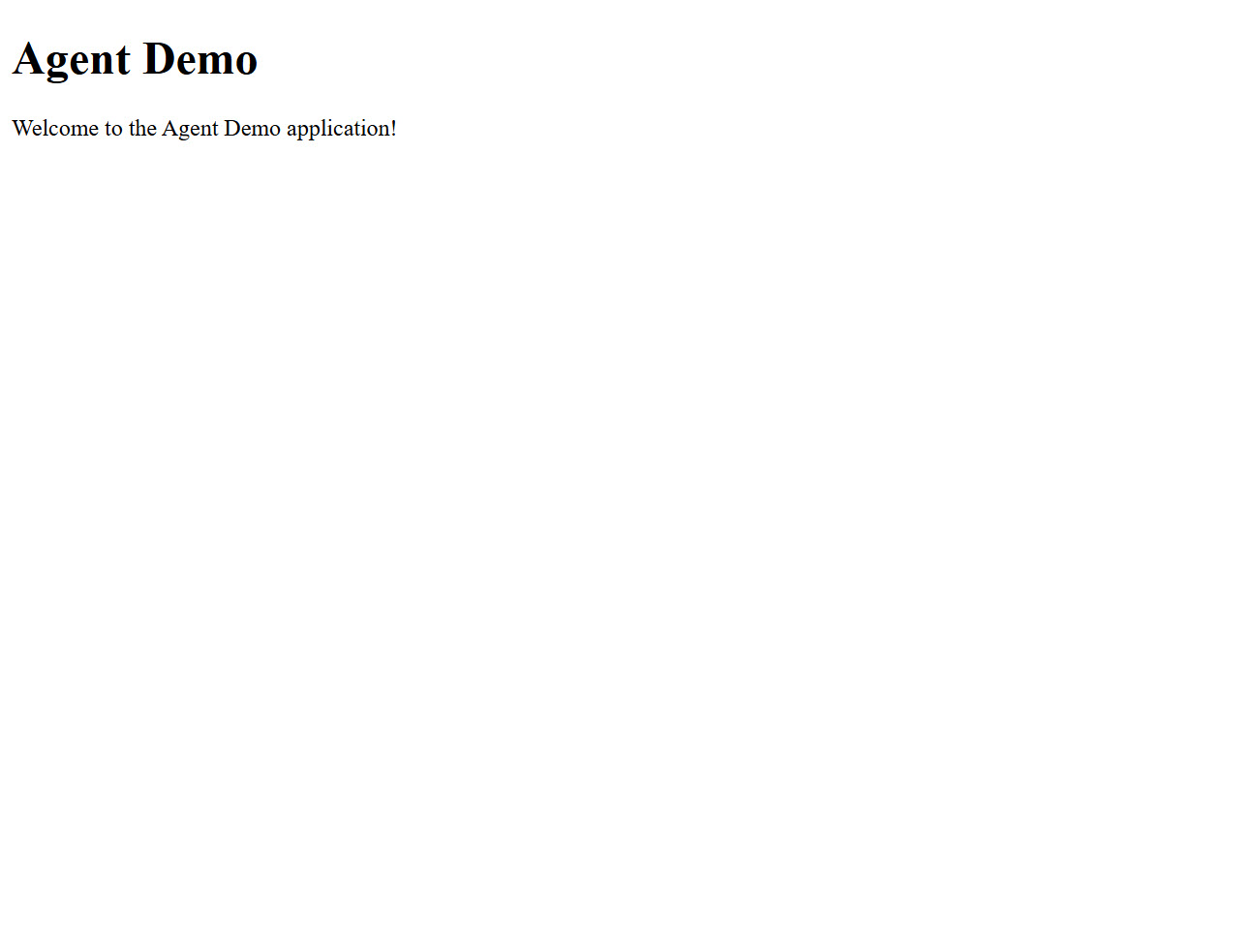
first version of the homepage
Editing existing code
I wanted to gauge its ability to add dependencies and makes changes to what already exists and so I prompted it with the following:
add mui to the project and make the main.tsx look more professional
It makes each change in a separate commit with a message describing the change. I see Add MUI dependencies and Update App with MUI components in the commit log and pulling latest reveals the result. Additionally, it informs me of what I need to do:
Now you’ll need to:
- Pull these changes
- Run
npm installto install the new MUI dependencies- Run
npm run dev
I follow these instructions and see the following result:
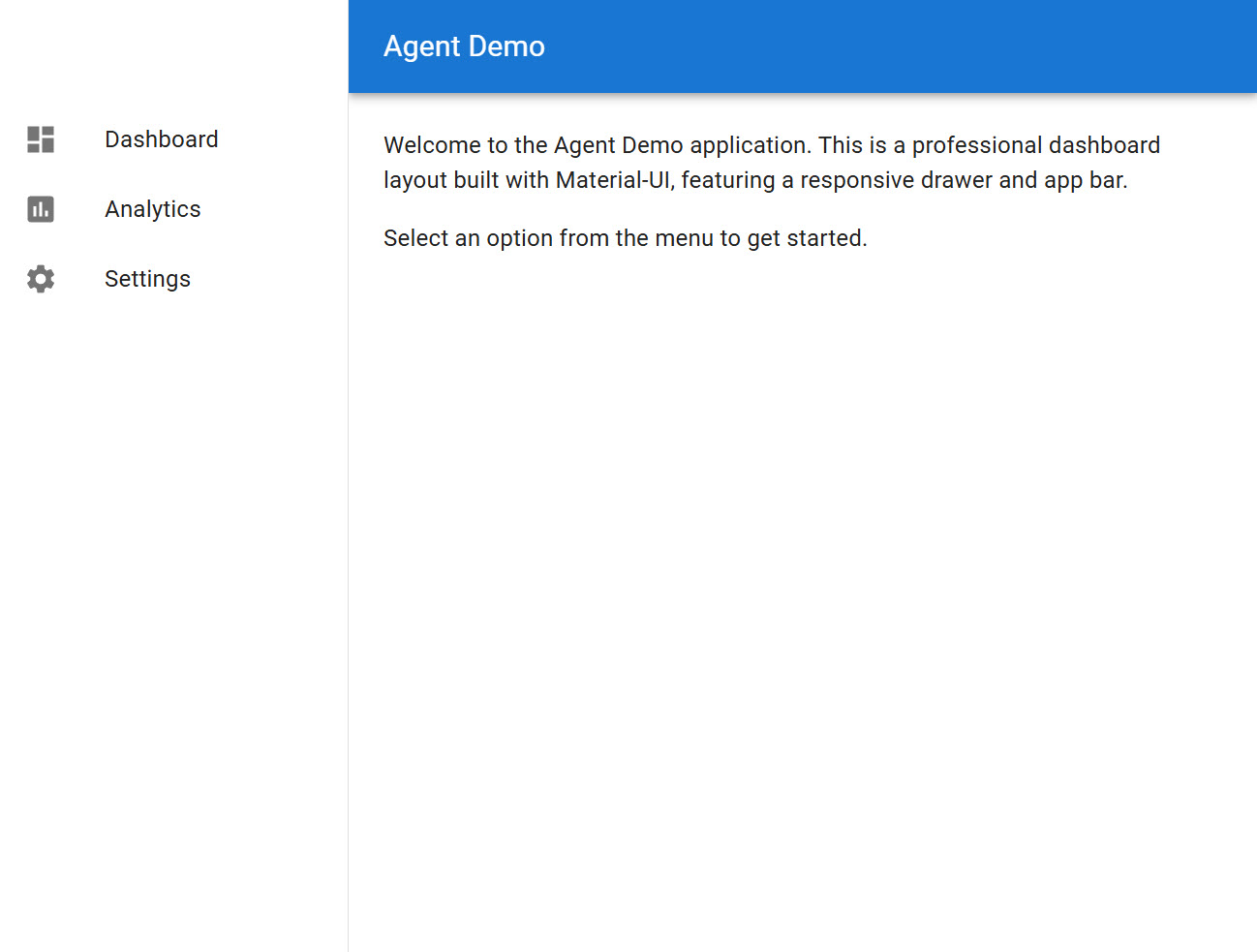
professional looking page
At this stage I decide to go full non-technical-stakeholder and without thought for any prior time or effort, I demand a rewrite of the main page:
ok - but now update the main page:
- remove the column/app bar
- use dark mode
- add like a some kind of centered, rotating svg design
- the whole page should be more centered
- add some much larger text on either side of the rotating svg that points out its a demo page
The agent does not complain, and continues to quickly make clean commits with each change, bending to my tyrannical whims:

after a rewrite
Improving my workflow
As the agent continues to correctly respond and make changes to the codebase, the bottleneck in this workflow is the time it takes me to stop the running dev server, pull latest, install new dependencies, and restart the dev server. I ponder whether the agent can help me improve this, and so I prompt it with the following:
I like this workflow, but every time you make a change, i have to stop the dev server, pull the git changes and then restart vite. Is there anything that could be done via rollup or vite functionality where that could be automated, for example by listening to a github webhook or something?
I’m kind of hoping that it can magically integrate github webhooks with vite’s hot module reload and I’m very much expecting it to fail. However not only does it succeed it does so quickly and impressively. It writes an express server that will git pull and npm i when called. It then updates vite config to proxy calls from a /webhook endpoint to the express server. It then adds a dev:watch npm script.
It also gives me the steps I need to configure the webhook in GitHub (I’m guessing the GitHub MCP server doesn’t yet have this capability, otherwise it could have done it itself), and informs me that if I’m running locally I’ll need to run npx ngrok http 3001. The ngrok command won’t work on its own because ngrok requires an API key and/or to authenticate first, however everything else is correct and I’m fairly astounded at the result. I don’t need to touch the shell anymore, I just prompt the tool and once it’s finished vite displays the changes.
Integrating a public API
I wanted to test the tool’s ability to integrate other APIs, but also to flex its search capability via the brave search MCP server I had configured.
Find a free public api that provides random dog facts. Write a component, in a new file, that on first render fetches and displays the random dog fact from the api. Include a button in the component, which when pressed, will request a new random dog fact.
It searched for, and found, the Dog API and integrated it without issue however it struggled with the component. It attempted to include an icon in the component, added a reference to lucide-react, but did not add it to package.json. I prompted it to do so, however it also had the name of the export for the icon wrong. After a couple of attempts it said…
Let me check the actual available exports from lucide-react.
…and updated it with the correct name. However, it did not appear to call any tool so definitely did not “check the actual available exports” even though it was able to resolve the issue. Without being prompted, it included the new component in the homepage and included a loading indicator when fetching the dog fact.
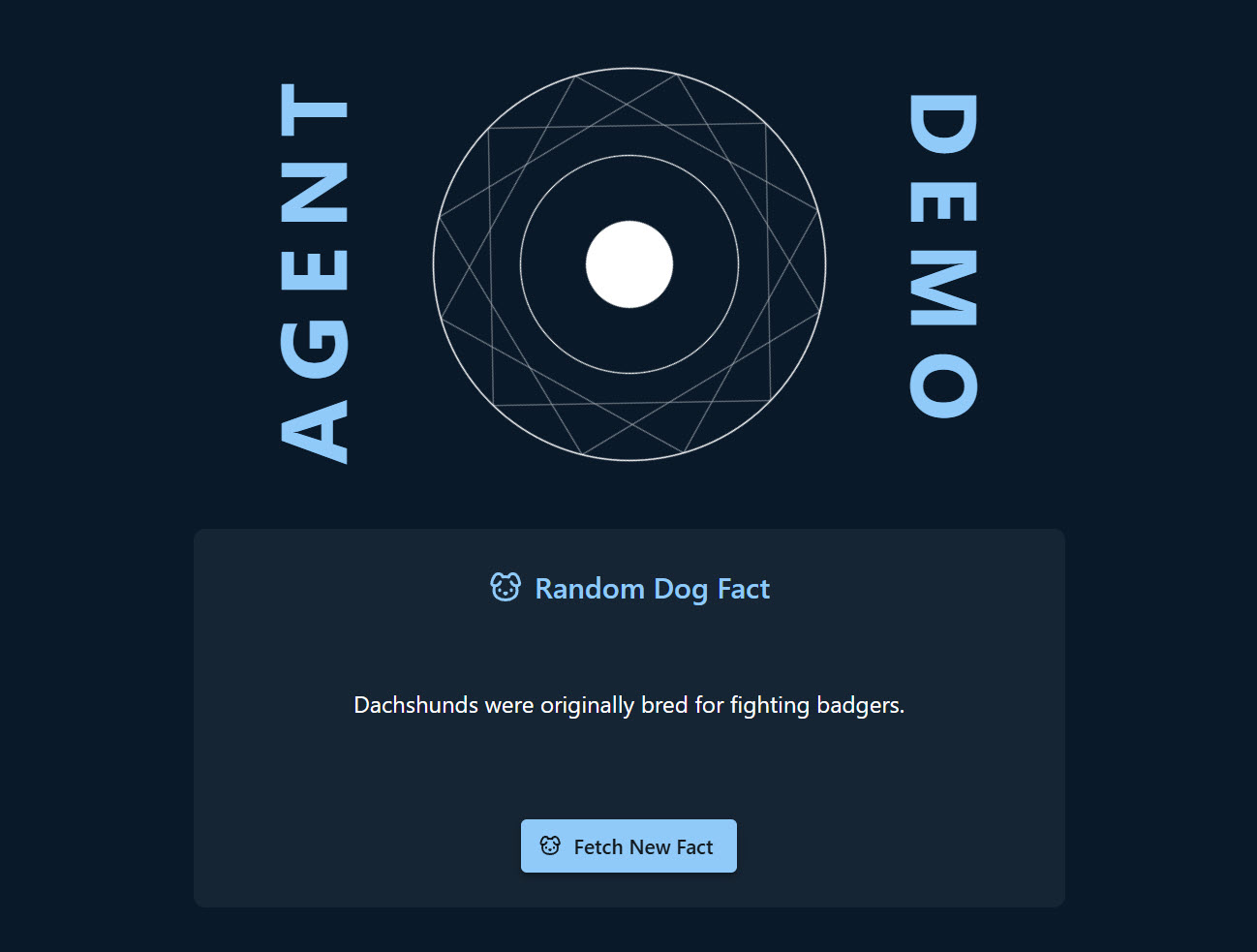
including the dog fact api
Adding a deployment pipeline
At this point I’m feeling pretty confident it’ll be able to add a pipeline to deploy the site to netlify. I prompt it with the following:
Add a github workflow to build and deploy the site to netlify.
It does so and advises the steps I need to do, including npx netlify-cli sites:create, the instructions for adding an API token to netlify and, the instructions for adding NETLIFY_SITE_ID and NETLIFY_AUTH_TOKEN to the GitHub secrets (against because the MCP server doesn’t have this action).
This results in a couple of problems: npm ci fails because there is no package.lock.json and npm run build fails due to an unnecessary React import in the DogFact component. My solution for package.lock.json was to run npm i locally and push the result. I don’t want to it to attempt to guess the lock file and the line count of that file would be pretty poor use of tokens. For the React import, I prompt it with the error message and it fixes DogFact but also realises it should fix App.tsx too and so does so.
The GitHub workflow action it chose, nwtgck/actions-netlify, spewed a bunch of errors but still passed (and deployed the site). That said, I didn’t like the console spam so prompted the agent to replace the action with a direct call to the netlify-cli and it did so without issue.
Adding tests
Keen to push the tool further, I prompt it to add vitest and react-testing-library to the project, write a test for the DogFact component, and include the test in the GitHub workflow. This does not work out of the box, and each time I see an error I post it back to the agent which then attempts to fix it. The are four errors in total and the agent is able to fix each of them after I post the error message back to it.
The result is a component test which includes a mock of fetch using correct vitest syntax. The test is included in the GitHub workflow and the pipeline passes.
Navigating GitHub
With the app up, tests passing, and a live deployment pipeline, it feels like everything is ready to start iterating on the project. Ignoring the manual workaround for package.lock.json it would appear the bottleneck in this workflow now is the interactions I have with the agent. Considering the agent can interact with GitHub, I ponder whether instead of chatting via the client, whether we could interact via GitHub issues, branches, and PRs and I have some luck doing so. It is able to search, read, respond and close issues.
When prompted to look for issues and resolve them, it can find them and raise a PR to resolve them. It does not appear to be able to see PR comments however, and prompting for it to do so at first resulted in it finding none, and then hallucinating one 🤦, but this may be because the GitHub MCP server does not implement this functionality.
Conclusion
In the past I’ve found that tools like Copilot can be useful for generating or editing code snippets, but I’ve never found a tool that can go beyond that without constantly failing and needing my technical expertise to resolve issues. This experience however has been a game changer. The speed and accuracy is very high, and (possibly more importantly) the ability to either auto-fix, or, fix as a result of me posting only an error message, is a huge time saver. Prompting for smaller changes and including technical guidance like which dependencies or patterns to use improves accuracy and still appears to be much faster than if I were to do it myself.
Context length is still a concern. The approach above was possible because the entire chat was in a single session. It is easy to reach the limit of Claude’s free version, and even though Claude Pro claims 5x more usage, after subscribing, I was still able to reach the limit with this chat transcript. Once the limit is reached, you’re blocked from further prompting for three to five hours. This means that the approach is not one of simply configuring MCP servers and prompting, but also of managing the context length and starting new sessions as required.
It also still appears to require a high level of technical expertise. Setup alone is likely to be a blocker for many, and technical guidance (or at least analysis) appears still required to prompt for better output. Seasoned developers may also struggle to get started as it requires a shift in mindset from writing code to prompting for code - in the early stages I had to get over the mental hurdle of describing what I wanted rather than just doing it.
Regardless, once a flow state is achieved, the speed at which I’m able to build with the tool is significantly faster than I could do myself. Even if this is just for bootstraping side projects or MVPs, the tool is definitely one I can see myself using more of in the future.